
Искусственный интеллект стремительно вошёл в промышленность и к 2026 году активно используется для оптимизации процессов, снижения себестоимости и повышения качества продукции. Чем шире внедрение, тем выше цена ошибок. Уже сейчас компании сталкиваются с утечками данных через LLM, манипуляциями поведением моделей, сбоями AI-агентов и публичными инцидентами, которые быстро расходятся в сети и бьют по бизнесу.
В этой статье рассмотрим сценарии применения ИИ промышленности, ключевые риски для бизнеса, поверхность атак на всех этапах жизненного цикла моделей, требования регуляторов и архитектуру безопасного промышленного ИИ.
В этой статье рассмотрим сценарии применения ИИ промышленности, ключевые риски для бизнеса, поверхность атак на всех этапах жизненного цикла моделей, требования регуляторов и архитектуру безопасного промышленного ИИ.
ИИ в производстве сегодня
ИИ перестал быть точечным инструментом и стал частью критичных бизнес-процессов. Он встроен в производство, логистику, поддержку клиентов и принятие решений. Это меняет характер рисков: теперь важна не только инфраструктура, но и поведение модели, данные и интеграции.
AI-агенты стали частью информационных систем:
1. ИИ переезжает в прод: он встроен в производственные контуры и «делает работу», а не просто консультирует.
2. ИИ влияет на данные, процессы и управленческие решения (иногда — автоматически через интеграции).
3. Риск смещается: важна не только безопасность инфраструктуры, но и поведение модели + контур её окружения.
4. Мультимодальность + интеграции → больше входов, больше доверенных действий, выше цена ошибки.
Ошибка/злоупотребление ИИ может стать инцидентом, когда вывод модели без достаточной верификации влияет на решения и действия ИС.
Кейсы инцидентов
Реальные инциденты с ИИ-системами уже затронули крупные компании:
1. Watsonville Chevrolet (2023)
Пользователь через prompt injection заставил чат-бота «согласиться» продать автомобиль за $1. Бот воспринял инструкцию как системную и подтвердил сделку.
Итог: репутационный ущерб и отключение AI-бота.
Тип атаки: direct prompt injection.
2. DPD UK (2024)
Через серию вопросов пользователь «разогрел» чат-бота до агрессивных и негативных высказываний о компании.
Итог: PR-кризис и отключение функции.
Тип атаки: multi-turn jailbreak.
3. Tesla Autopilot (2020–2024)
Наклейки на дорожных знаках приводили к ошибочной интерпретации скорости или игнорированию STOP.
Итог: потенциально опасные физические сценарии.
Тип атаки: adversarial examples в CV.
4. Microsoft 365 Copilot (2024)
Исследователи показали утечки данных между тенантами из-за логики retrieval без строгой проверки ACL.
Итог: cross-tenant data leakage.
Тип атаки: RAG retrieval bypass.
Поверхность атаки
Современный ИИ нельзя рассматривать как «чёрный ящик в вакууме». Это цепочка компонентов, каждый из которых может быть атакован.
Жизненный цикл ИИ как поверхность атак
Атаки возможны на каждом этапе жизненного цикла ИИ-системы:
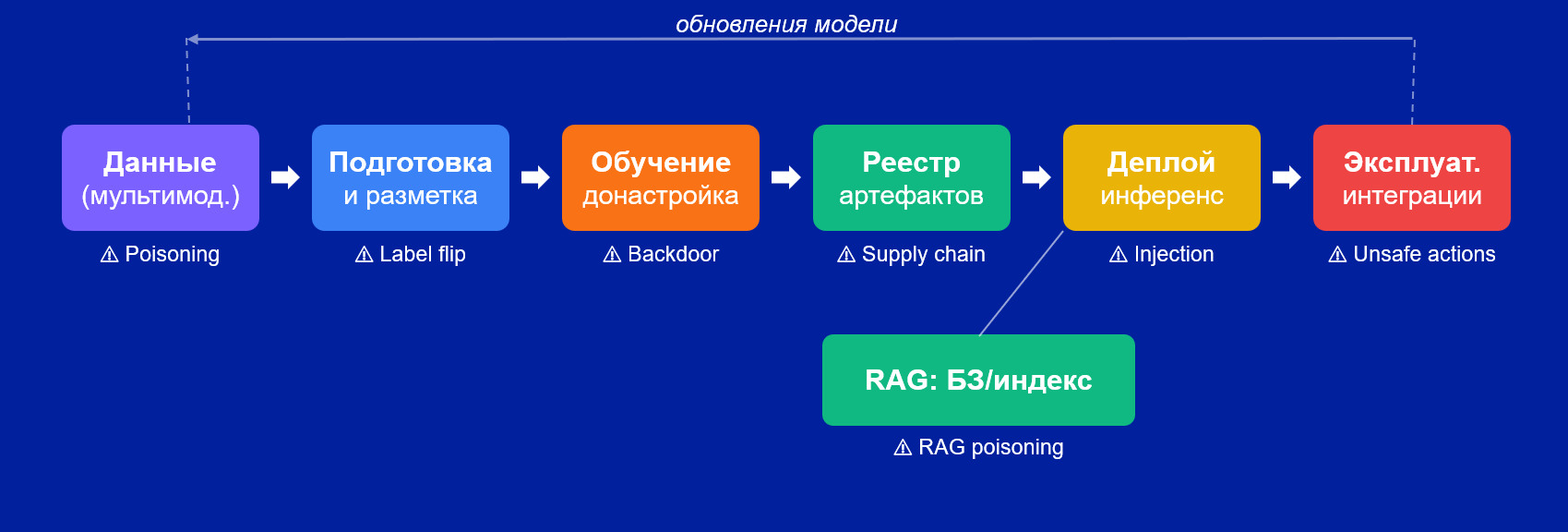
Атаки на данные: поверхность по модальностям
Схема атак по модальностям:
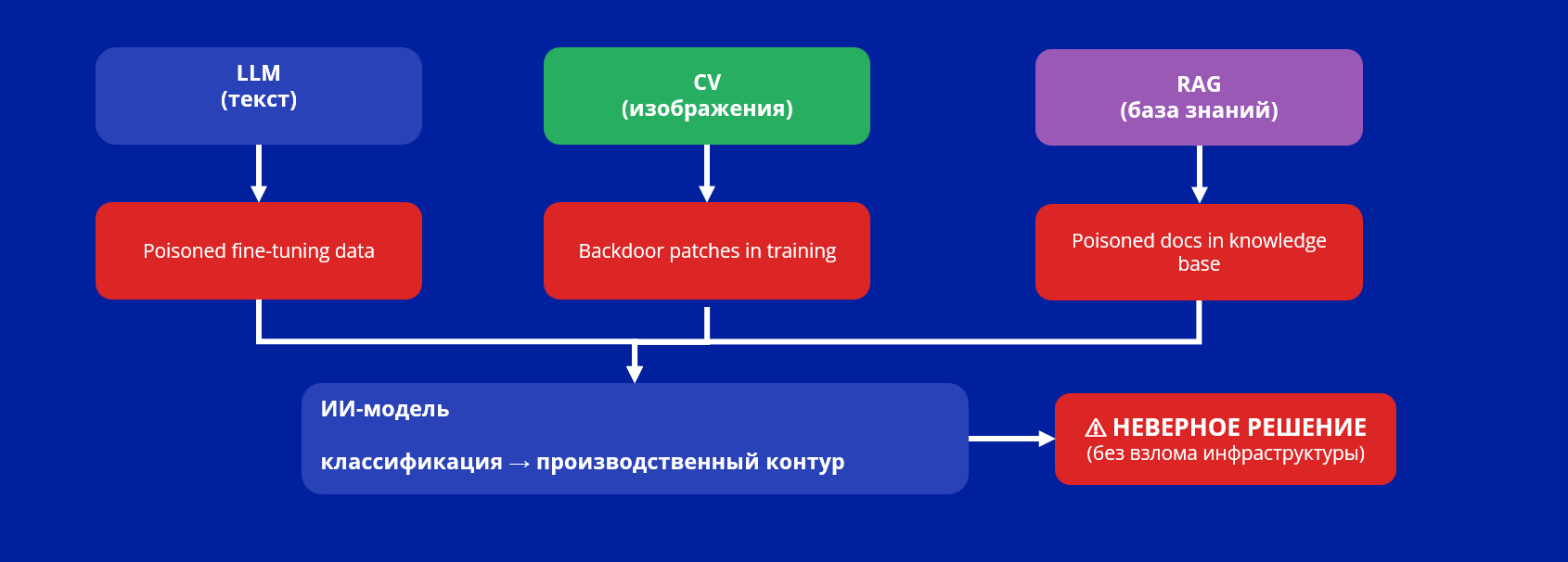
Посмотрим на схему выше. Есть три канала атаки по числу модальностей: LLM через отравленные данные fine-tuning, компьютерное зрение через backdoor-патчи и RAG через отравленные документы в базе знаний. Все они сходятся к одному результату — неверное решение ИИ-модели. Данные проходят классификацию и маршрутизацию в производственном контуре. Атака на любой канал приводит к тому, что часть системы теряет свою работоспособность. При этом инфраструктура полностью чистая, никакого взлома.
ML Supply Chain: Attack Surfaces
В классическом DevSecOps мы проверяем код. В ML нужно проверять артефакты, потому что модель — это фактически исполняемый код.
Цепочка поставки ML-моделей становится самостоятельной зоной риска:
Цепочка поставки ML-моделей становится самостоятельной зоной риска:
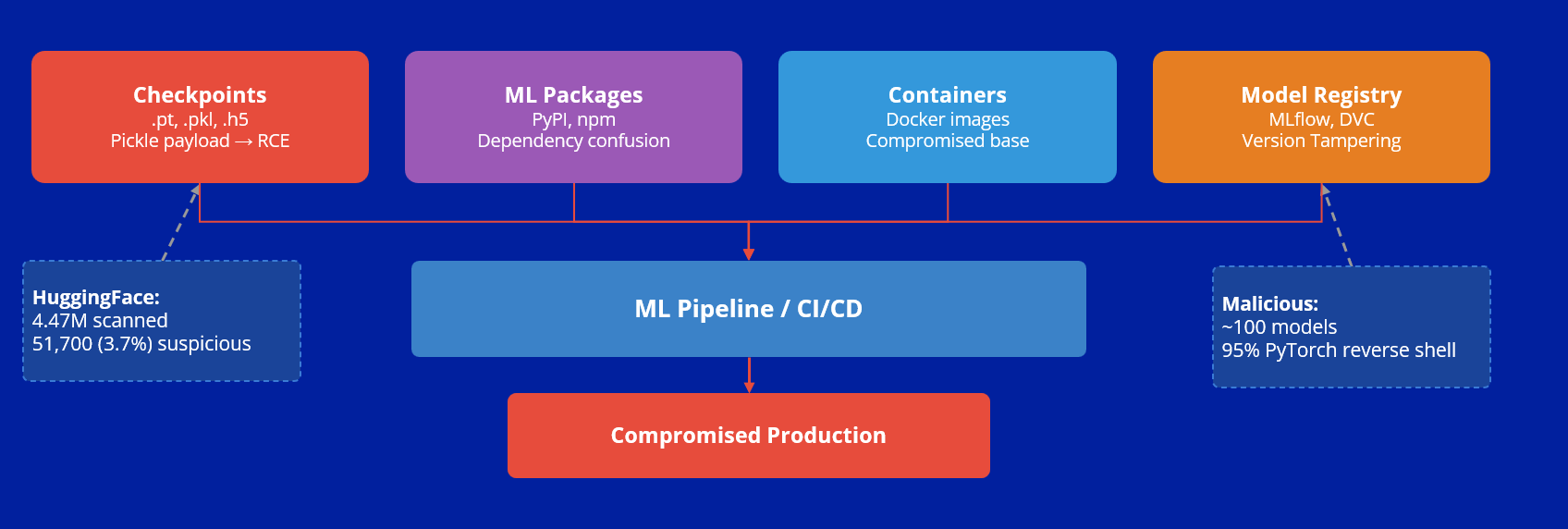
Важно: модель может быть скомпрометирована до того, как вы её загрузили.
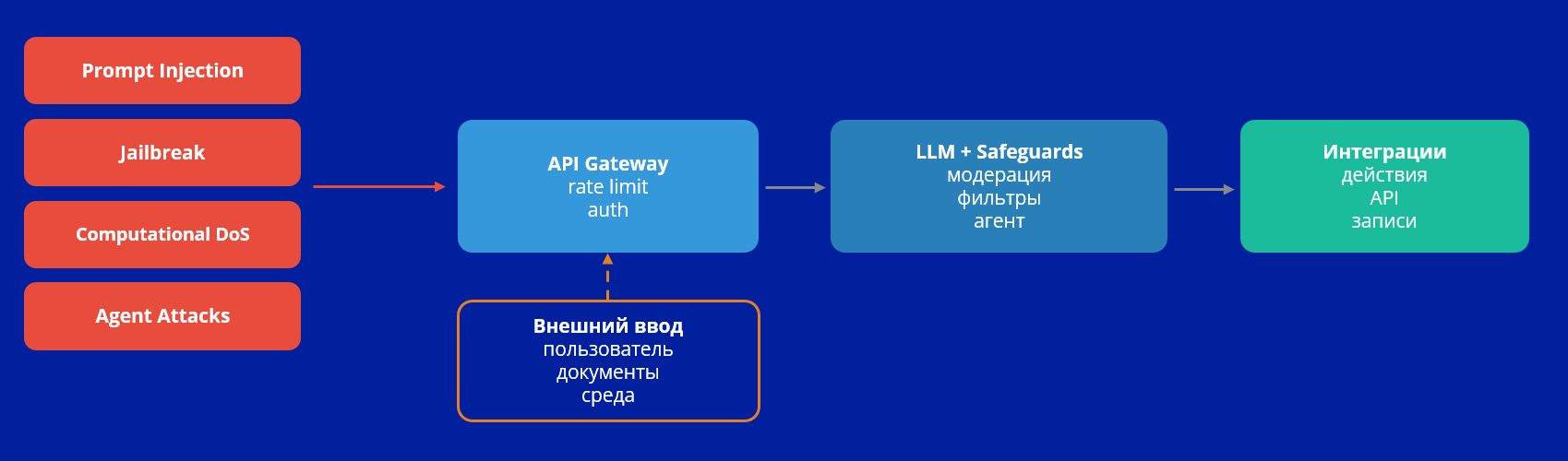
Runtime: поверхность атак
Атаки проходят через API Gateway с rate limiting, затем через LLM с safeguards, и выходят на интеграции. Даже без компрометации инфраструктуры система может демонстрировать управляемое поведение под воздействием входных данных.
На схеме типичная архитектура Runtime:
Базовые атаки на модели ИИ
Большинство угроз для современных AI-систем не связаны с прямым «взломом» инфраструктуры. Вместо этого злоумышленники воздействуют на входные данные, контекст или окружение модели, заставляя её вести себя нежелательным образом. Именно поэтому атаки на ИИ часто выглядят как обычное взаимодействие с системой, но приводят к утечкам данных, нарушению политик или выполнению нежелательных действий.
Prompt Injection
Это внедрение инструкций в prompt/context, заставляющее модель игнорировать правила.
Инъекция может быть прямая, когда инструкция приходит прямо от атакующего, или непрямая, когда инструкция спрятана во внешнем контенте.
Последствия:
- Утечка данных клиентов;
- Выдача клиенту недопустимого контента (агит-контент, политизированные галлюцинации).
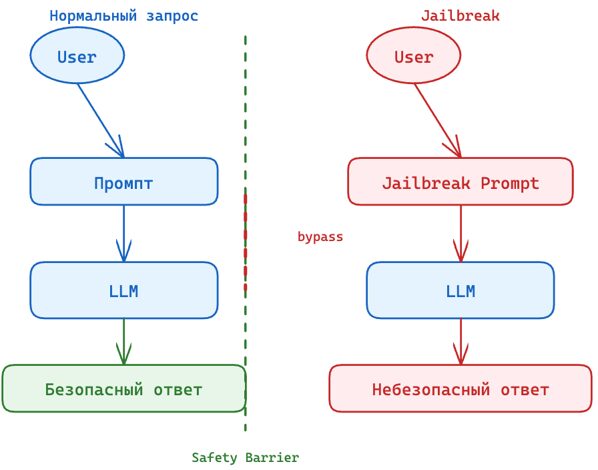
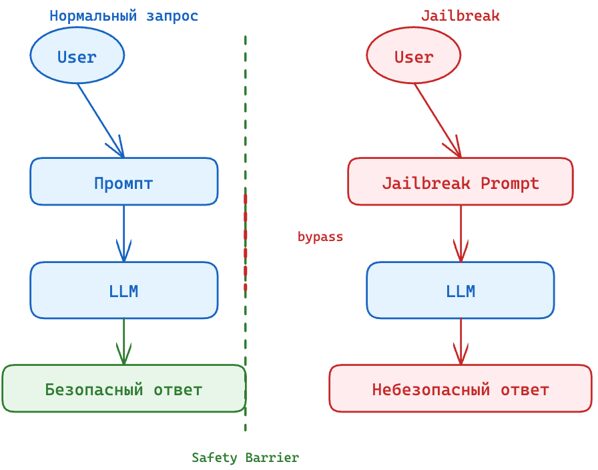
Jailbreak
Это набор приемов, при которых атакующий через обычный текстовый ввод вынуждает модель игнорировать встроенные правила безопасности (guardrails). В OWASP jailbreak рассматривается как разновидность Prompt Injection (LLM01).
Последствия:
- Обход системных инструкций и бизнес-ограничений;
- Выполнение вредоносных действий через API;
- Внедрение protestware или участие в цепочке атаки на систему.
Риски для бизнеса
Использование LLM и AI-систем в продакшене формирует не только технологические, но и прямые бизнес-риски. Ошибка модели или её целенаправленная компрометация может быстро перейти из технической проблемы в финансовые, юридические и репутационные потери.
Основные риски:
·Утечка данных через LLM. Наиболее критичный сценарий. Может привести к штрафам по GDPR или 152-ФЗ вплоть до 4% годового оборота компании.
·Репутационный ущерб. Публичные инциденты с ИИ быстро становятся вирусными: скриншоты уходят в соцсети и СМИ, формируя негативный информационный фон. Восстановление доверия в таких случаях часто занимает месяцы.
·Регуляторные штрафы. По мере усиления регулирования компании всё чаще сталкиваются с проверками и требованиями доказать безопасность своих AI-систем.
·Операционный сбой. Компрометация ИИ-агента может привести к некорректным действиям в бизнес-процессах — от ошибочных решений до остановки критичных операций.
·Кража интеллектуальной собственности. Через модели можно извлечь system prompt, бизнес-логику или данные дообучения, что фактически эквивалентно утечке ключевых конкурентных преимуществ.
Требования регуляторов в области безопасности ИИ
В России сейчас активно формируется набор стандартов, методик и отраслевых требований, которые определяют, как должны проектироваться, внедряться и эксплуатироваться AI-системы с точки зрения риска, качества и доверия.
ГОСТ
Применение на добровольной основе или обязательно, если упоминается в нормативном документе:
- ГОСТ Р 59898–2021 «Оценка качества систем искусственного интеллекта» (26.11.21) — понятие качества СИИ, классификация характеристик и показателей, включая параметры управления рисками.
- ГОСТ «Искусственный интеллект в критической информационной инфраструктуре. Общие положения».
- ГОСТ Р 59276–202 «Системы ИИ. Способы обеспечения доверия».
Указы Президента
Рекомендательное применение:
- Указ №490 «О развитии искусственного интеллекта в РФ» (10.10.19), п. 5 пп. «ц», п. 51, п. 53 — терминология в области ИИ и его безопасности.
ФСТЭК России
Применение на добровольной основе или обязательно, если упоминается в нормативном документе:
- Приказ ФСТЭК №117 «Требования о защите информации, содержащейся в ГИС» (11.04.25) — безопасное использование систем ИИ.
- Методика ФСТЭК «Анализ защищённости информационных систем» (25.11.25).
- БДУ «Угрозы безопасности информации систем ИИ».
Отраслевые нормы
Обязательное или рекомендательное применение:
- Кодекс этики в сфере ИИ (Альянс в сфере ИИ) (05.23).
- Кодекс этики ЦБ РФ в сфере разработки и применения искусственного интеллекта на финансовом рынке (06.25).
- Росстандарты в области ИИ для клинической медицины, здравоохранения, образования, транспорта и др.
Архитектура безопасного промышленного ИИ
В основе безопасного промышленного ИИ лежит сочетание проверенных методологий и практических стандартов, которые помогают превратить разрозненные меры защиты в единую систему. Рассмотрим ключевые фреймворки, подходы к управлению и уровни контроля, которые формируют такую архитектуру на практике.
Внедрение фреймворков AI Security
При проектировании защищённых AI-систем важно опираться не только на внутренние практики компании, но и на внешние фреймворки безопасности. Они задают структурированный подход к управлению рисками, помогают классифицировать угрозы и выстраивать единые требования к моделям, данным и инфраструктуре.
Важно: Фреймворк ≠ нормативный акт. Потребуется адаптация под организацию и увязка с будущими требованиями ФСТЭК.
Распределение ответственности
Эффективная безопасность AI-систем невозможна без чёткого определения зон ответственности и правил управления:
·Владельцы активов — данные, модель/версии, контекст, интеграции/действия.
- Правила изменений — кто и как обновляет модель, артефакты, контекст, политики.
- Политики взаимодействия — правила запрос/ответ, допустимые задачи, объяснимость.
- Контуры знаний — наполнение, обновление, пересечения доменов/прав.
- Распределение ответственности — кто отвечает за качество/безопасность ответов и последствия.
- Допуски и доступы — классы пользователей/ролей, квоты/лимиты.
- Критерии инцидента — что считаем инцидентом ИИ, кто принимает решение о реакции.
Контроли по жизненному циклу
Разработка и эксплуатация ИИ-систем сопряжена с рисками на каждом этапе её жизненного цикла. Чтобы минимизировать угрозы, необходимо внедрить систему контролей, «закрывающую» ключевые точки уязвимости.
Обучение / донастройка:
- контроль артефактов (модели, чекпоинты, конфигурации) с помощью систем управления версиями (DVC, GitLFS);
- тестирование поведения модели перед выпуском: аудит на adversarial attacks, утечки данных, проверку edge cases.
Деплой / поставка:
- управление версиями моделей и зависимостей (контейнеризация — Docker, системы управления образами — Harbor, Quay);
- контроль целостности артефактов (подписи моделей с SSL/TLS, проверка хэшей);
- Supply Chain Security: отказ от pickle deserialization, использование safetensors, сканирование зависимостей (Snyk, Dependabot).
Эксплуатация:
- ограничение области решений (whitelist подходов, запрет опасных операций);
- критерии «недостоверности» ответов: метрики качества (confidence score), мониторинг аномалий (Prometheus/Grafana), защита от poisoning attacks;
- правила реакции на инциденты: логирование подозрительных запросов, автоматическое отключение модели, процедуры расследования и восстановления.
AI Gateway: контроль на границе
AI Gateway (ИИ-шлюз) — это слой безопасности между пользователем и LLM/AI-агентом. Он контролирует входящие запросы и ответы модели, обеспечивая соответствие политикам безопасности и использования.
На входе Gateway выявляет PII, jailbreak-попытки, токсичный контент и нарушения ACL/квот. После обработки запроса моделью система дополнительно проверяет ответ на утечки данных, небезопасный контент и hallucination.
Помимо фильтрации, ИИ-шлюз отвечает за применение политик доступа и аудит событий. Реализовать его можно через open-source решения (LLM Guard, NeMo Guardrails, guardrails-ai) или коммерческие платформы вроде Lakera Guard и Protect AI.
Важно учитывать, что AI Gateway не является «серебряной пулей». Исследования 2025 года показали, что guardrails могут обходиться в whitebox-сценариях вплоть до 100% успешности атак. Поэтому Gateway следует рассматривать как один из слоёв стратегии defense-in-depth, а не как самостоятельный механизм полной защиты.
Тестирование безопасности ИИ
AI Security Testing — это практика анализа LLM и AI-агентов на устойчивость к атакам, утечкам данных и небезопасному поведению. Тестирование помогает выявлять регрессии после обновлений моделей, проверять систему на prompt injection, data poisoning и другие классы рисков, а также встраивать security-проверки в CI/CD и процессы red teaming.
Для анализа защищенности ИИ используются инструменты вроде PyRIT (Microsoft), garak (NVIDIA), promptfoo, Giskard и AppSec.GenAI. Они позволяют масштабировать adversarial testing и запускать тысячи атакующих сценариев автоматически.
Исследования 2025 года показывают, что автоматизированное тестирование достигает 69.5% эффективности против 47.6% у ручного подхода. При этом prompt injection покрывается сравнительно хорошо, тогда как model inversion и system exploitation всё ещё остаются слабо тестируемыми направлениями. Поэтому даже при высокой автоматизации человеческий expertise остаётся критически важным для поиска сложных и нестандартных атак.
MLSecOps: масштабирование защиты
MLSecOps — это интеграция практик безопасности в ML/AI pipeline по аналогии с DevSecOps. Цель подхода — встроить контроль рисков непосредственно в жизненный цикл моделей: от данных и обучения до деплоя и эксплуатации.
Ключевые практики MLSecOps:
Выводы
Регуляторная среда в области AI постепенно ужесточается. В фокусе появляются требования вроде ФСТЭК №117 и внимание к объектам ЗОКИИ, что делает вопросы AI security не только техническими, но и комплаенс-задачей.
Поверхность атак охватывает весь жизненный цикл систем: от данных и моделей до RAG и агентных сценариев. Но эти риски управляемы. Комбинация подходов управления, контрольных точек безопасности и регулярного тестирования позволяет существенно снизить вероятность инцидентов и контролировать поведение системы в продакшене.
Практически это сводится к нескольким шагам: провести инвентаризацию моделей, данных и источников контекста, назначить владельцев за каждый ключевой артефакт, оценить текущую зрелость процессов и зафиксировать пробелы. Далее выделить наиболее критичные риски и сфокусироваться на внедрении защитных мер в первую очередь там, где потенциальный ущерб максимален.